


基本信息
- 项目名称:
- 高性能中文垃圾邮件过滤系统
- 来源:
- 第十一届“挑战杯”国赛作品
- 小类:
- 信息技术
- 大类:
- 自然科学类学术论文
- 简介:
- 随着电子邮件的广泛应用,伴随而来的垃圾邮件问题日益严重。它不仅消耗网络资源、占用网络带宽、浪费用户的宝贵时间和上网费用,而且严重威胁网络安全,已成为网络公害,带来了严重的经济损失。中国互联网协会反垃圾邮件中心发布的2007年第四季度反垃圾邮件调查报告显示,垃圾邮件在规模上不断增长,2007年第四季度中国网民平均每周收到的垃圾邮件比例为55.65%。迫切需要有效的技术解决垃圾邮件泛滥的问题。 邮件过滤任务本质上可以看作是一个在线二值分类问题,即将邮件区分为Spam(垃圾邮件) 或Ham(正常邮件)。近几年,基于机器学习的文本分类法在垃圾邮件过滤中发挥了巨大的作用,典型的方法包括贝叶斯方法、支持向量机(SVM,Support Vector Machine)方法、最大熵方法、PPM(Prediction by Partial Match)压缩算法等。由于这些方法过滤正确率高、成本低,因此机器学习方法称为当前的主流方法。应用机器学习方法对垃圾邮件进行过滤时涉及到3个问题:模型选择、特征抽取(邮件表示)以及训练方法。 从模型上看,机器学习技术可以粗略分为生成模型(如贝叶斯模型)和判别模型(如SVM、最大熵模型)。在相关领域——文本分类中,判别模型的分类效果比生成模型的分类效果要好,特别在没有足够多的训练数据的时候,这种现象更明显。在生成模型方面,著名的Bogo系统就是基于贝叶斯模型的,在TREC评测中作为基准(Baseline)系统。用于数据压缩的CTW(context tree weight)和PPM(Prediction by Partial Match)等压缩算法被引入到了垃圾邮件过滤。CTW和PPM是数据压缩中使用的动态压缩算法,其原理是根据已经出现的数据流预测后面要出现的数据流,预测的越准,所需的编码也就越少,并据此进行分类。2004年,Hulten和Goodman在PU-1垃圾邮件集上做实验,证明了在邮件过滤上,判别模型的分类效果比生成模型的分类效果要好。不严格的在线支持向量机(Relaxed Online SVM)克服了支持向量机计算量大的问题被用于解决垃圾邮件过滤的问题,并在TREC 2007评测中取得了很好效果。Goodman和Yih提出使用在线逻辑回归模型,避免了SVM、最大熵模型的大量计算,并取了与上一年度(2005年)最好结果可比的结果。 在特征抽取(即邮件表示)上,邮件的文本内容是当前过滤器处理的重点。大多数英文过滤器以词作为过滤单元,中文过滤器则是以词作为过滤单元。由于垃圾邮件对文本的内容进行了变形,使得上述方法存在缺陷。非精确的字符串匹配被用于解决这个问题,但该方法只对英文垃圾邮件过滤有效,无法直接用于中文垃圾邮件过滤。在信息检索领域的字符级n元文法被引入垃圾邮件过滤,并在TREC评测中取得优于词袋(Bag of word)假设的结果。鉴于大量垃圾邮件将文本内容转换为图像,基于图像分析(Image Analysis)的过滤技术近年来得到重视。 在训练方法上,最简单也是最常用的训练方法就是对每一封邮件都进行训练。这种方法在实际应用中已经获得了很好的效果,但是有两个问题。第一个问题是内容相近的邮件可能被多次训练,增加资源的耗费。第二个问题是会出现过度训练的问题,当某些特征在特征库中已经有足够多的计数时,再过多的进行训练会导致准确率的下降。改用TOE(Train On Error)方法后,仅当邮件被误判时才进行训练,这种方法只能用于判别学习模型。这样可防止过度训练、减小空间占用并提高速度。尽管过度训练会极大的影响过滤器的准确率,但TOE训练法在另一个方向走过了头,仅对误判的邮件进行训练导致过滤器训练数据不足,其对准确率仍有影响。TONE(Train On/Near Error)在TOE基础上加以改进,预设一个分数界限,当邮件得分与判断阀值之差的绝对值在界限之内时,即使正确判断也进行训练。 本文采用逻辑回归模型、字节级n元文法和TONE训练方法进行中文垃圾邮件过滤。本文描述的系统参加了中国计算机学会主办的SEWM(Search Engine and Web Mining)2008垃圾邮件过滤评测,获立即反馈、主动学习、延迟反馈全部在线评测项目的第一,性能优于第二名100倍左右;在另外两个中文测试集(SEWM 2007和TREC05c)上也显著优于当年评测的最好结果。
- 详细介绍:
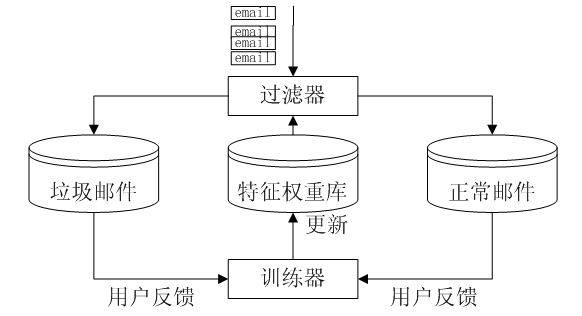
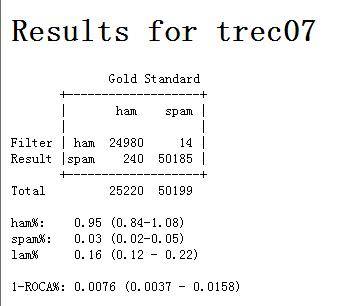
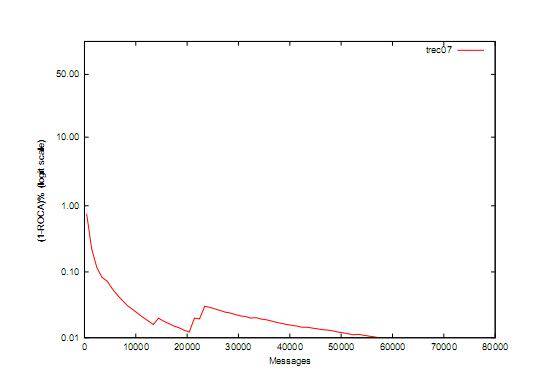
- 1 逻辑回归模型 逻辑回归(Logistic Regression,LR)模型,和SVM一样,是一种判别学习模型。判别学习模型与以贝叶斯为代表的生成模型有本质差异。传统生成模型认为数据都是某种分布生成的,并试图根据这种分布建模。采用最大似然估计(maximum likelihood estimation,简称MLE)来求解模型参数,并用平滑算法来解决数据稀疏问题。这种方法仅当以下两个条件都满足时才是最优的:第一,数据的概率分布形式是已知的;第二,存在足够大的训练数据时才能采用最大似然估计(maximum likelihood estimation,简称MLE)来求解模型参数。但在实际应用中,这两个条件很多时候无法满足。判别学习模型是与生成模型相对应的一类建模方法。其假设条件比MLE弱得多,只要求训练数据和测试数据来自同一个分布即可。而且,判别学习算法的目标往往与实际应用的评价标准密切相关(如使模型在训练数据上的错误率最小化)。因此判别学习模型的性能往往要优于生成模型。逻辑回归模型和SVM本质上是一致的,都是在寻找具有最大间隔的超平面,不同的是损失函数(经验风险)的定义不同。但从计算复杂度上看,逻辑回归模型的计算复杂要明显低于SVM,其分类速度要也比SVM快得多。 在基于内容的邮件过滤系统中,影响一封邮件是垃圾邮件还是非垃圾邮件的因素是该邮件中的特征。 应用逻辑回归模型,可以根据邮件的特征判断该邮件是垃圾邮件的概率(公式如picture1所示)。 2 基于字节级n元文法的特征提取 邮件过滤的依据是邮件的特征,特征项的定义,是影响分类性能的关键因素。和文本分类问题相比,邮件过滤有其特殊之处。反垃圾邮件技术在进步,发送垃圾邮件的技术也在不断地提高。由于巨大的利益驱动,狡猾的垃圾邮件发送者对其电子邮件信息进行多方面的伪装,通过各种手段将垃圾邮件伪装为正常邮件。同时,大量垃圾邮件以图像的形式出现,导致传统方法失效;单纯的依赖邮件的文本内容对含有病毒的垃圾邮件无能为力。 针对垃圾邮件特征提取面临的问题,提出了基于字节级n元文法的特征提取方法。字节级n元文法在处理邮件文本内容时,提取了邮件的文本内容,在处理邮件的附件、所包含的图片等组成成分时,提取了它们的二进制特征,因此能够在一个简单的框架下处理以往很难处理问题。采用字节级n元文法提取邮件特征,避免了繁杂的邮件解析、汉字编码转换等工作,并使系统具有处理图像、病毒邮件的能力。 字节级n元文法,将邮件按字节流进行大小为n的滑动窗口操作,形成长度为n 的字节片断序列,每个字节片断称为gram。n元文法 按字节流进行采用长度为n 的窗口切分,如:hellowolrd,按照n=4时进行滑动窗口切分为:hell、ello、llow、lowo、owol、wolr、olrd这样7个4-gram。采用n元文法信息作为邮件特征具有以下特点:无需任何词典支持,无需进行分词处理;无需语言学先验知识;无需对邮件进行预处理,将邮件当作无差别的字节流对待,不用考虑文字编码的问题,同时具有处理复杂文件的能力,如HTML格式邮件、图像文件、压缩文件。与以词字、词组等为特征元素相比,这样定义特征元素能有效防止了垃圾邮件信息的可能被绕过的情况。如product进行文字变形,变换为p!roduct,pro_duct,prod-uct等等,基于词字、词组的过滤器就可能识别不出该特征,而基于字节的n元文法仍可以有效识别出该特征。例如,当n=4时,product进行特征抽取如下:prod、rodu、oduc、duct;当product文字变形后变为prod-uct时进行特征抽取如下:prod、rod-、od-u、d-uct、-uct;两者共有的特征是prod。当出现特征prod时,则该完整的单词为product的概率比只捕捉到特征prod时的概率要大得多。 中文使用至少2个字节表示一个字(如GB2312使用两个字节表示1个汉字,GB18030使用两个字节或四个字节表示1个汉字),不使用空格作为词的分隔符,因此,如果对汉字进行文字变换程度太大的话,是很难让人读懂的,如“胡锦涛”,常见的变形文字是“胡.锦.涛”、“hu锦涛”等,这种文字变形使得典型的以词为过滤单元的方法失效。但在n元文法下,能够提取有效特征,表明了该邮件的性质。以词作为过滤单元,词作为最小的能自由运用的语言单位,将有助于过滤性能的提高,需要进行编码识别和分词,但分词的准确度难以保证,尤其是未登录词的识别性能难以得到保证,同时难以处理文字变形;若以字作为过滤单元,不需要进行分词,实现起来比较容易,但如字的语义表达能力较弱,上下文信息太少。 在实验中使用了字节级4-gram,并且每一封邮件仅取前3000个4-gram。邮件的特征值为布尔值,即邮件包含某个4-gram,其值为1,否则为0。 3 TONE训练方法 TONE(Train On or Near Error)方法也被称之为Thick Threshold方法,该方法是在TOE基础上加以改进,预设一个分数界限,当邮件得分与判断阀值之差的绝对值在界限之内时,即使正确判断也进行训练。 现在说明该方法的应用。对于本文采用的逻辑回归模型,当邮件的得分大于等于0.5时,就判断成垃圾邮件;反之,当当邮件的得分小于0.5时,就判断成正常邮件。采用TONE训练方法,在下述两种情况下进行训练:(1)过滤器分类错误;(2)如果设定阈值为0.1,则得分介于0.4到0.6之间的邮件都需要进行训练。 TONE训练方法只对分类面附近的样本进行训练,通过算法1将分类错误和在分类面附近的样本向“安全区域”调整。直观上,这个过程与支持向量机模型有异曲同工之妙。支持向量机模型在寻找最大化最近距离的分类面(即最优分类面);在TONE方法中,恰当地设置阀值,可以起到相同的作用。据我们所知,尚未有讨论TONE方法和最优分类面关系的文献。 本文采用梯度下降的方法更新特征库中特征的权重。使用梯度下降方法时,选取合适的特征学习速率以保证适当的学习速率。具体实现如picture2所示。 垃圾邮件的在线过滤模式如picture3所示。 评估结果如picture4所示。 评测结果的(1-ROCA)%图如pricture5所示。
作品图片


作品专业信息
撰写目的和基本思路
- 随着电子邮件广泛应用,垃圾邮件问题日益严重。它不仅消耗网络资源、占用网络带宽、浪费用户的宝贵时间和上网费用,而且严重威胁网络安全,已成为网络公害,带来了严重的经济损失。2007年第四季度中国网民平均每周收到的垃圾邮件比例为55.65%,迫切需要有效的技术解决垃圾邮件泛滥的问题。 故设计此系统通过一定的技术手段对邮件内容进行分析,进而判断邮件是否为垃圾邮件。
科学性、先进性及独特之处
- 1.采用逻辑回归模型。计算复杂度低,分类速度快。 2.基于字节级n元文法的特征提取。有效解决了垃圾邮件特征获取的问题,应用该特征不仅简化了特征提取,还使得过滤器能够处理图像、病毒邮件的能力,为大幅提高垃圾邮件过滤器的性能奠定了基础。 3.采用TONE训练方法。减轻了系统对训练数据的需求,提高了系统的效率,同时还提高了系统的鲁棒性。
应用价值和现实意义
- 该方法的性能极佳,能有效地对邮件的内容进行分析,进而判断一封邮件是否为垃圾邮件。 该系统可做为网站、个人用户及有过滤邮件需要的机构的邮件过滤工具,从一定程度上解决相关人员在垃圾邮件方面的困扰,节省人力、物力。 如果此系统得到推广,将能从一定程度上解决垃圾邮件泛滥的现状,节省网络资源、用户的宝贵时间和上网费用,减少由垃圾邮件带来的经济损失。
学术论文摘要
- 设计并实现了基于在线过滤模式高性能中文垃圾邮件过滤系统,能够较好地好识别不断变化的垃圾邮件。以逻辑回归模型为基础,本文提出了字节级n元文法提取邮件特征,并采用TONE(Train On or Near Error)方法训练建立过滤器。在多个中文垃圾邮件过滤评测数据上的实验结果表明,本文过滤器的性能在TREC 06数据上优于由于当年评测的最好成绩,在SEWM 07立即反馈上1-ROCA值达到了0.0000%,并以绝对优势获得了SEWM 08评测的所有在线过滤任务的第一名。
获奖情况
- 此系统参加了中国计算机学会主办的SEWM(Search Engine and Web Mining)2008垃圾邮件过滤评测,获立即反馈、主动学习、延迟反馈全部在线评测项目的第一,性能优于第二名100倍左右;在另外两个中文测试集(SEWM 2007和TREC05c)上也显著优于当年评测的最好结果。
鉴定结果
- 附加材料中的“SEWM2008-task3-overview.ppt”中的“测评相关说明”和“测评结果分析”两部分有详细说明。
参考文献
- [1]V. N. Vapnik. Statistical Learning Theory[M]. New York, USA: John Wiley & Sons, Inc. 1998:1-18. [2]A. Bratko, B. Filipič, G.V. Cormack et al. Spam Filtering Using Statistical Data Compression Models[J]. The Journal of Machine Learning Research archive, 2006,7:2673-2698 [3]G. Hulten and J. Goodman. Tutorial on junk e-mail filtering[C]. The Twenty-First International Conference on Machine Learning (ICML 2004). 2004: (Invited Talk, icmltutorialannounce.htm) [4]D. Sculley, G. M. Wachman. Relaxed Online SVMs for Spam Filtering[C]. The 30th Annual International ACM SIGIR Conference (SIGIR’07). New York, NY, USA:ACM, 2007:415-422 [5]J. Goodman and W. Yih. Online Discriminative Spam Filter Training[C]. Third Conference on Email and Anti-Spam (CEAS 2006). 2006:113-115. ( [6]D. Sculley. Advances in Online Learning-based Spam Filtering [D]. Medford, MA, USA: Tufts University.
同类课题研究水平概述
- 邮件过滤任务本质上可以看作是一个在线二值分类问题,即将邮件区分为Spam(垃圾邮件) 或Ham(正常邮件)。近几年,基于机器学习的文本分类法在垃圾邮件过滤中发挥了巨大的作用,典型的方法包括贝叶斯方法、支持向量机(SVM,Support Vector Machine)方法、最大熵方法、PPM(Prediction by Partial Match)压缩算法等。由于这些方法过滤正确率高、成本低,因此机器学习方法称为当前的主流方法。应用机器学习方法对垃圾邮件进行过滤时涉及到3个问题:模型选择、特征抽取(邮件表示)以及训练方法。 从模型上看,机器学习技术可以粗略分为生成模型(如贝叶斯模型)和判别模型(如SVM、最大熵模型)。在相关领域——文本分类中,判别模型的分类效果比生成模型的分类效果要好,特别在没有足够多的训练数据的时候,这种现象更明显。在生成模型方面,著名的Bogo系统就是基于贝叶斯模型的,在TREC评测中作为基准(Baseline)系统。用于数据压缩的CTW(context tree weight)和PPM(Prediction by Partial Match)等压缩算法被引入到了垃圾邮件过滤。CTW和PPM是数据压缩中使用的动态压缩算法,其原理是根据已经出现的数据流预测后面要出现的数据流,预测的越准,所需的编码也就越少,并据此进行分类。2004年,Hulten和Goodman在PU-1垃圾邮件集上做实验,证明了在邮件过滤上,判别模型的分类效果比生成模型的分类效果要好。不严格的在线支持向量机(Relaxed Online SVM)克服了支持向量机计算量大的问题被用于解决垃圾邮件过滤的问题,并在TREC 2007评测中取得了很好效果。Goodman和Yih提出使用在线逻辑回归模型,避免了SVM、最大熵模型的大量计算,并取了与上一年度(2005年)最好结果可比的结果。